Archives Unleashed Notebooks
The Archives Unleashed Notebooks are a prototype method for working with derivatives generated by the Archives Unleashed Toolkit. They allow you to interactively explore and filter the domain count information, extracted full text, and network visualization data generated by the Toolkit.
To use them now, please visit the GitHub repository here and follow the instructions.
You can play with a few live demos:
- An example of using Python’s pandas library to explore web archive derivatives [GitHub] [Google Colab]
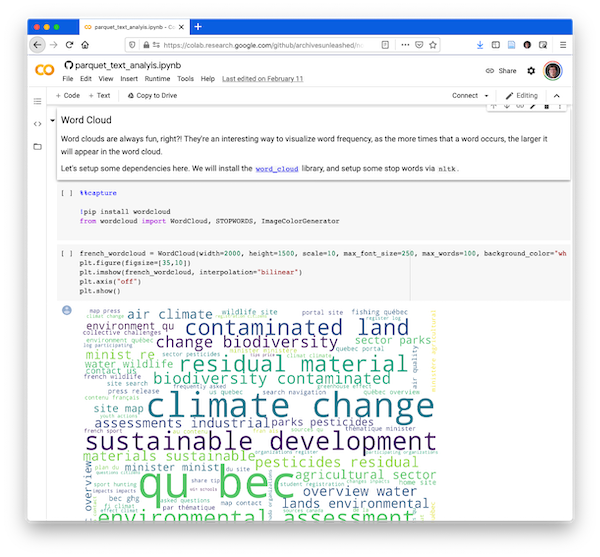
- An example of text analysis in action on a web archive [GitHub] [Google Colab]
- An example of using PySpark in the Cloud [GitHub] [Google Colab]
You can read more about the thinking behind the notebooks in our Medium post, “Cloud-hosted web archive data: The winding path to web archive collections as data.”