Archives Research Compute Hub (ARCH)
Introduction
ARCH (Archives Research Compute Hub) is a research and education service that helps users easily build, access, analyze, publish, and preserve web archive datasets at scale.
ARCH was made possible by a highly integrated collaboration between the Archives Unleashed Project and the Internet Archive’s Archiving and Data Services team and generous support from the Andrew W. Mellon Foundation. The partnership underscores a shared commitment to fostering innovative research and enhancing the usability and accessibility of web archives at scale. As this collaboration concludes in June 2023, stewardship of the ARCH platform and services will be undertaken by the (Archive-It Services, Internet Archive).
Features
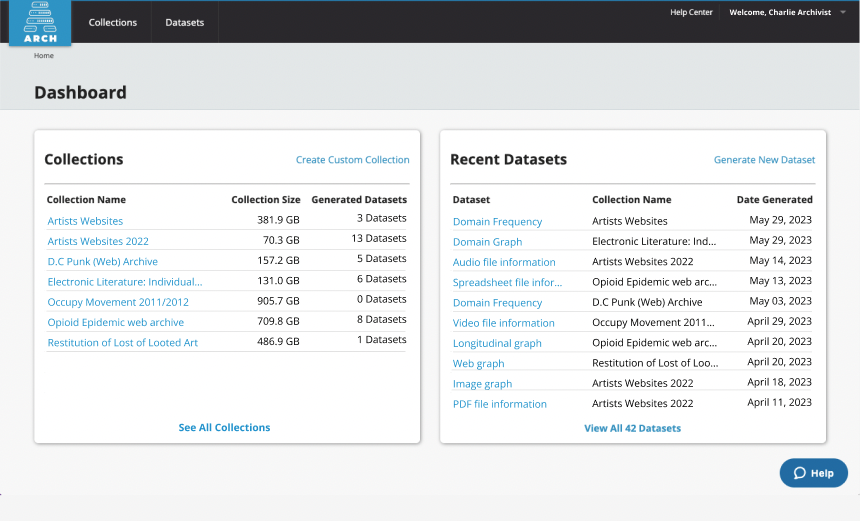
- Intuitive, interactive, user-friendly stand-alone browser-based app
- Generating over a dozen research dataset types (e.g., full text, images, hyperlink network graphs, PDFs, audio files etc.) from web archive collections into widely compatible CSV files
- Build custom collections with filtering capabilities
- Download generated datasets directly in-browser or via API
- Research-ready datasets compatible with computational environments and tools (e.g. Jupyter Notebooks, Gephi, Voyant)
- Direct connection between datasets and Google Colab Notebook to conduct initial exploratory analysis
- Review content collection through in-browser visualizations and data previews
- Publish datasets in line with best practices in reproducible research to the Internet Archive. All datasets will be preserved in perpetuity.
- Browse extensive documentation to support your use of ARCH, guidance on paring datasets with computational tools, and sharing research examples and use case
Getting Started
To begin your journey with ARCH, please reach out using this form.
Learn more:
- ARCH Information Page: https://webservices.archive.org/pages/arch
- ARCH User Documentation: https://support.archive-it.org/hc/en-us/articles/360061122492-Introduction-to-the-Archive-It-Research-Services-Cloud
ARCH is also open-source and available at https://github.com/internetarchive/arch.

![]()
Citing Archives Unleashed
Your citations help to further the recognition of using open-source tools for scientific inquiry, assists in growing the web archiving community, and acknowledges the efforts of contributors to this project.
How to cite the Archives Unleashed Project, Toolkit or ARCH in your research:
| Nick Ruest, Jimmy Lin, Ian Milligan, and Samantha Fritz. 2020. The Archives Unleashed Project: Technology, Process, and Community to Improve Scholarly Access to Web Archives. In Proceedings of the ACM/IEEE Joint Conference on Digital Libraries in 2020 (JCDL ‘20). Association for Computing Machinery, New York, NY, USA, 157–166. DOI: https://doi.org/10.1145/3383583.3398513 | |
| Helge Holzmann, Nick Ruest, Jefferson Bailey, Alex Dempsey, Samantha Fritz, Peggy Lee, and Ian Milligan. 2022. ABCDEF: the 6 key features behind scalable, multi-tenant web archive processing with ARCH: archive, big data, concurrent, distributed, efficient, flexible. In Proceedings of the 22nd ACM/IEEE Joint Conference on Digital Libraries (JCDL ‘22). Association for Computing Machinery, New York, NY, USA, 1–11 DOI: https://doi.org/10.1145/3529372.3530916 |